Unless you have been hiding behind a 🗿 for the last few years “Breaking down the monolith” has been a theme across Software industry. More than often application architectures evolved like below and Kubernetes has been heart and center of this evolution.
To
What is Kubernetes?
Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation.
As per Kubernetes.io
Architecture
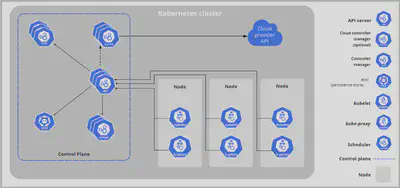
When you deploy Kubernetes, you get a cluster.
A Kubernetes cluster consists of a set of worker machines, called nodes, that run containerized applications.
Nodes in a Kubernetes cluster may be physical, or virtual. There are two types of nodes:
A Control-plane-node type, which makes up the Control Plane, acts as the “brains” of the cluster.
A Worker-node type, which makes up the Data Plane, runs the actual container images (via pods).
Next we will look👀 under the hood at a high level.
Control Plane
The Control Plane components make global decisions about the cluster (for example, scheduling, maintaining desired state). Can be setup as a Multi-Master H/A control plane. The master node does not run any containers in general. Let’s breakdown further:
Kube-ApiServer
Front-end to the control plane
Exposes the API (REST)
Consumes JSON/YAML
Cluster Store (K-V)
Persists cluster state and config
Based on etcd
Performance is critical
Have recovery plans in place
Kube-ControllerManager
Controller of controllers
Node controller
Deployment controller
Endpoints/EndpointSlice controller…
Watch loops
Reconciles observed state with desired state
Kube-Scheduler
Watches API Server for new work tasks
Assigns work to cluster nodes
Affinity/Anti-affinity
Constraints
Taints
Resources…
Nodes
Node components run on every node, maintaining running pods and providing the Kubernetes runtime environment
Describe what you want (Desired state) in a manifest file.
It’s Declarative since it does not specify the HowTo part, leaving that for Kubernetes to figure out.
Kubernetes does support both Imperative i.e (specifying the HowTo part) and Declarative operations.
But Declarative is the preferred method in Production since it can be version controlled and host of other goodness.
The Imperative way is absolutely not the approach to use in Production but it’s very handy to go fast, test things up, and it can also help to generate manifest files (using a combination of the –dry-run and -o yaml flags). Also see Pod Deployment.
Internally within the Control Plane the following events would occur to get and maintain the Desired state.
Client/Kubectl calls ApiServer{} with your Desired state,
ApiServer{} persists that in the K-V store,
Scheduler schedules work to the Worker nodes to create Desired state,
Controller would run Watch/Reconciliation loops to maintain Desired state.
Atomic unit
The Atomic unit of scheduling/scaling in the Kubernetes world is the Pod. Meaning you cannot run your containerized workload directly, it needs to be wrapped in a Pod.
So what does a Pod give?
🥁 It gives a Shared Execution Environment for the Containers i.e
a collection of things the <app> needs for it to run, things like an IP address, port, filesystem, shared memory and so on.
Unless you have a Specialist Use Case where a <hlpr> container enhances the <app> container functionality, it’s best practice to keep the containers loosely coupled, i.e in all typical application use cases you would connect them via Networking.
Scaling in Kubernetes happens by adding/removing Pods, not Containers. Pods are the smallest deployable units of computing that you can create and manage in Kubernetes.
Pod deployment is Atomic operation i.e
🤔 A pod would only report up and running to the Control Plane only when all of it’s containers are UP. It’s a all or nothing proposition.
Containers in a Pod are always scheduled the same Node.
Annotations
Labels
Policies
Resources
Co-scheduling containers
Stable Networking with Services
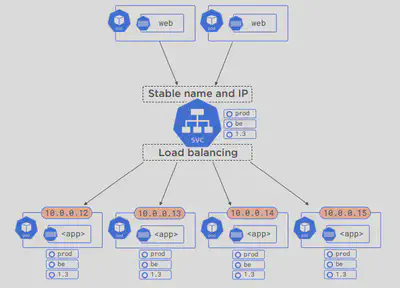
We learnt earlier that each Pod gives a Shared Execution Environment which includes an IP address.
But since we can scale ↕️, or they may crash and be replaced, their IP address would keep on changing. Well that means any client application cannot/should not rely on the Pod IP address.
🥁 Enter Service objects. It is a high‑level stable abstraction point for multiple Pods and it provides a stable IP and DNS name. A Service object is just a Kubernetes API object like a Pod or Deployment or anything else, meaning we define it in a YAML manifest, and we create it by throwing that manifest at the ApiServer{}.
The way that a Pod belongs to a service or makes it onto the list of Pods that a service will forward traffic to and do loadbalancing is via labels. When deciding which Pods to load balance traffic to, the service uses a label selector like below.
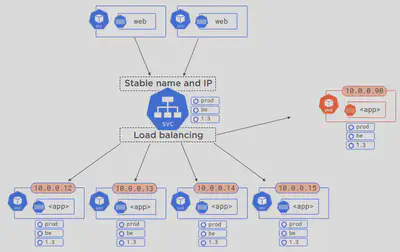
Note: That means a completely unrelated pod could potentially get routed to also:
When it comes to updating the backend Pods, all that needs to happen is update the label selector for the Service object like so:
Only sends traffic to healthy Pods
Can do session affinity
Can send traffic to endpoints outside the cluster
Can do TCP and UDP
Deployments
Pods don’t scale or self heal or any of such dynamic goodness.
🥁 Enter Deployments (for Stateless apps) or similar high‑level controllers like Stateful Sets,DaemonSets, Jobs, Cron Jobs and more and each are for different use cases.
Deployments add some of the functionality like self‑healing, scaling, rolling updates, rollbacks, and a bunch more. Deployments work together with another controller called a ReplicaSet controller, and it’s actually the job of the ReplicaSet to manage the number of replicas. Then, the Deployment acts as a higher level controller above or around the replica set and manages them. So, we’ve got a bunch of nesting going on here:
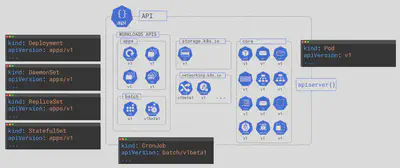
🥁 Well, each one of these is an object in the Kubernetes API.
The API contains the definition and feature set of every object in Kubernetes so that when we post the corresponding manifest to the API server, it knows we’re defining say a Deployment object in this version of the API, and it knows what all of these fields are and how to build what we need.
APIServer{} is a Control Plane feature that exposes the API over a secure, RESTful endpoint. So, it supports all the major HTTP verbs like POST, and GET, and all of that.
It is also versioned and split into multiple subgroups for ease of access.
Kubernetes Objects and Resources
Kubernetes objects are entities that are used to represent the state of the cluster.
Since the K8s API is versioned and split into multiple subgroups, it plays a huge role in versioning the pod manifests:
A representation of a specific group+version+kind is an object. For example, a v1 Pod, or an apps/v1 Deployment. Those definitions can exist in manifest files, or be obtained from the apiserver.
A specific URL used to obtain the object is a resource. For example, a list of v1 Pod objects can be obtained from the /api/v1/pods resource. A specific v1 Pod object can be obtained from the /api/v1/namespaces/<namespace-name>/pods/<pod-name> resource.
An object is a record of intent – once created, the cluster does its best to ensure it exists as defined. This is known as the cluster’s “desired state.”
It’s the Kubernetes resources that allow you to define the desired state for containerized workloads in a Kubernetes cluster.
Kubernetes is always working to make an object’s “current state” equal to the object’s “desired state.” A desired state can describe:
What pods (containers) are running, and on which nodes
IP endpoints that map to a logical group of containers