GitHub Actions Cheat Sheet
Overview
GitHub Actions is a continuous integration and continuous delivery (CI/CD) platform that enables automated build, test and deployment pipelines. GitHub Actions also enables the execution of non-CI/CD type automation on a repository, like adding a label when someone creates a new issue on the repository.
GitHub Actions supports Linux, Windows and macOS operating systems
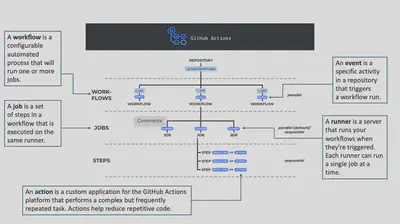
Event(s)
A specific activity in a repository that triggers a workflow execution
Examples:
- A user creates a
pull request - A user opens an
issue - A user pushes a
committo a repository - Other example events that trigger workflows
[skip ci] or [ci skip] in the commit message. GitHub recognizes this phrase and will not trigger the CI workflow for that commit.Workflow(s)

A configurable automated process:
- Made up of one or more jobs defined by a YAML associated to a repository
- Found in
.github/workflows - A given repo can have multiple workflows
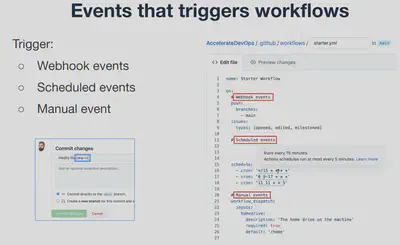
- Runs when:
- Triggered by an event in a repository
- Triggered manually
- Triggered via another workflow (workflows can reference other workflows)
- Posting to a REST API
- Per a defined schedule
Examples:
- A workflow to build and test pull requests
- A workflow to deploy your application every time a release is created
- A workflow to add a label every time someone opens a new issue
Runner(s)
- A server that runs your workflows when they are triggered
- A given runner can execute a single job at a time
- Ubuntu Linux, Windows and macOS provided (hosted) by GitHub
- Each workflow runs on a fresh,
newly-provisionedvirtual machine - Runners come in different configurations to meet specific needs
- Users can leverage GitHub hosted or self-hosted runners
Job(s)
A set of steps in a workflow that execute on the same runner
Each job runs within a virtual machine (runner) OR container
Jobs run in parallel by default but can be configured to depend upon one another using
needskeywordEach job contains one or more step(s)
Steps can be a shell command
[run]or an action[uses]Runs when:
- Invoked within a workflow
- When the prior / dependent job within the workflow finishes
- Simultaneously with another job within the workflow
- In the context of a matrix
Examples:
- Separate, unique build jobs for different architectures
- A packaging job
- A deployment job
jobs: job_1: runs-on: ubuntu-latest steps: - run: echo "The job was triggered by a ${{ github.event_name }} event." - run: echo "The drive is '${{ github.event.inputs.homedrive }}'." - run: echo "The environment is '${{ github.event.inputs.environment }}'." - run: echo "The log level is '${{ github.event.inputs.logLevel }}'." - run: echo "Should run the matrix? '${{ github.event.inputs.run_matrix }}'." job_2: runs-on: ubuntu-latest needs: job_1 steps: - run: echo "Status ${{ job.status }}" job_3: runs-on: ubuntu-latest needs: job_1 steps: - run: echo "Services ${{ job.services }}" job_4: runs-on: ubuntu-latest needs: [job_2, job_3] steps: - run: echo "Status ${{ job.status }}" - name: Step Summary run: echo "All the jobs completed in ${{ github.ref }} branch!" >> $GITHUB_STEP_SUMMARY
You can set some custom Markdown for each job summary to display and group unique content, such as test result summaries, failures and so on. GITHUB_STEP_SUMMARY is an unique environment variable for each step in a job.
echo "{markdown content}" >> $GITHUB_STEP_SUMMARY
Step(s)
Granular execution of a job
Steps can be a shell command (
run) or an action (uses)Data can be shared from one step to another
When using the
runcommand it runs in the same process/same directory in ashellBy default, GitHub Actions uses
bashon Linux andpwshon Windows. If you want to specify a different shell, you need to use theshellkeyword.The availability of some shells may depend on the runner environment (e.g., Ubuntu, Windows, MacOS). Always ensure that the shell you are trying to use is available in your runner’s environment.
Runs when:
- Invoked within a job
- When the prior step finishes
Examples:
- A step that builds your application
- A step that pushes an artifact to the artifact repository

Action(s)
A reusable step is an Action
Reduces the amount of repetitive code written in Workflow files
Actions can be self-created / customized, or provisioned from the GitHub Marketplace.
Lives in a independent public repository.
Can be written in JavaScript/Typescript(
NodeJS).May use GitHub Actions Toolkit for command line argument parsing, passing parameters, interacting with the GitHub API.
The most minimal action definition is composed of a
nameand arunsobject to define how the action is executed and what file to run.name: "HelloWorld Action" description: "Says Hello!" author: "Avijit Chatterjee" runs: using: "node20" main: "dist/index.js" branding: icon: "aperture" color: "green"
Could be written as a
Dockercontainer that does the the action logic and reference it from the registry like say Docker Hub when invoking the action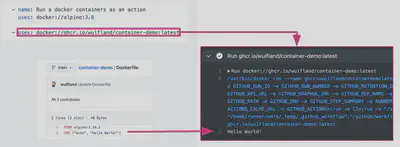
Could be a
CompositeAction where you would basically combine multiplerunandusescommand steps into a single action.- Here’s a simple example of a composite GitHub action that runs a set of commands to set up a
Node.jsenvironment, install dependencies, and run tests.name: 'Setup Node.js' description: 'Sets up a Node.js environment, installs dependencies, and runs tests' inputs: node-version: description: 'Node.js version to use' required: true default: '14' working-directory: description: 'The directory to run commands in' required: false default: '.' outputs: test-results: description: 'The result of the test run' runs: using: "composite" steps: - name: Set up Node.js uses: actions/setup-node@v3 with: node-version: ${{ inputs.node-version }} - name: Install Dependencies run: npm install working-directory: ${{ inputs.working-directory }} - name: Run Tests run: npm test working-directory: ${{ inputs.working-directory }} continue-on-error: true id: tests - name: Set Output for Tests run: echo "test-results=${{ steps.tests.outcome }}" >> $GITHUB_ENV
- Here’s a simple example of a composite GitHub action that runs a set of commands to set up a
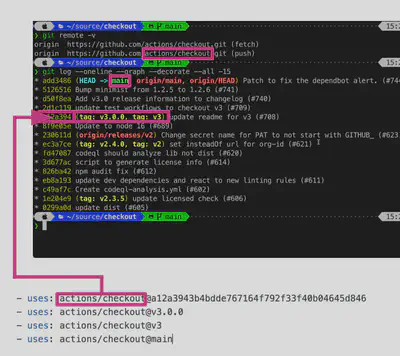
Whichever way you create it the
Actiondefinition is stored in theaction.ymlfile, put directly in the root of the repository.Use
Semanticversioning to build and maintain your Actions. When you or others refer/use your Action you would do so like:- {owner}/{repo}@{ref}
- {owner}/{repo}/{path}@{ref}
- where ref could be SHA / Tag / Branch
Pass variables to Action
with: The
withkeyword allows you to specify inputs for actions. These inputs can be defined in the action.yml file and can have default values, data types, and descriptions. This method is typically used for passing configurable parameters that the action will use.env: The
envkeyword is used to set environment variables that can be accessed in the action. Environment variables are global within the job and can be useful for passing sensitive data (e.g., secrets) or shared configurations.
Examples:
- Pull a given git repository for GitHub
- Set up the correct toolchain for a build environment
- Establish authentication to a cloud provider
Context
Every workflow execution has access to different Context information during runtime. Contexts are a way to access information about workflow runs, variables, runner environments, jobs, and steps. Each context is an object that contains properties, which can be strings or other objects.
You can access contexts using the expression syntax: ${{ <context> }}.
We have already seen some usage like this where we output the branch name from the github context object
echo "All the jobs completed in ${{ github.ref }} branch!" >> $GITHUB_STEP_SUMMARY
We can look at all the different context objects available in a workflow and we can do this by converting the objects to JSON and storing them in an environment variable on each step. Lastly, we’ll output that environment variable with a simple echo statement:
Create a new workflow with the below code:
.github/workflows/context.yaml.name: Context Information on: push: branches-ignore: main jobs: show-context: name: Show Context timeout-minutes: 5 runs-on: ubuntu-latest steps: - name: Dump Event Information env: CONTEXT_ITEM: ${{ toJson(github) }} run: echo "GitHub context ${CONTEXT_ITEM}" - name: Dump Job Information env: CONTEXT_ITEM: ${{ toJson(job) }} run: echo "job context ${CONTEXT_ITEM}" - name: Dump Runner Information env: CONTEXT_ITEM: ${{ toJson(runner) }} run: echo "runner context ${CONTEXT_ITEM}" - name: Dump Step Information env: CONTEXT_ITEM: ${{ toJson(steps) }} run: echo "step context ${CONTEXT_ITEM}"Add&Commityour changes, thenPushyour branch.Go to your repository and view the
Actionstab to see the execution against your published branch.The result will be an execution of the workflow whenever any changes are pushed EXCEPT on the
mainbranch.Contextinformation is viewable in the output so that you can understand how to utilize those values in your workflows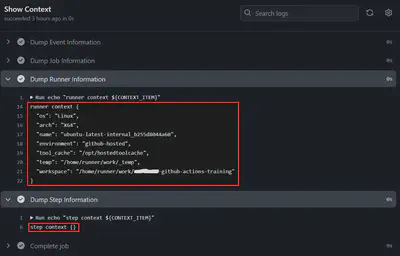
steps context empty?In GitHub Actions, the steps context is only populated with information about the steps that have already run in the current job and have an id specified.
Let’s apply the necessary property id so we can pass data between steps:
name: Context Information
on:
push:
branches-ignore: main
jobs:
show-context:
name: Show Context
timeout-minutes: 5
runs-on: ubuntu-latest
steps:
- name: Provide Some Step Outputs
id: step-outputs
run: echo "TRUE_STATEMENT=Possums are terrible." >> $GITHUB_OUTPUT
- name: Dump Step Information
env:
CONTEXT_ITEM: ${{ toJson(steps) }}
run: echo "${CONTEXT_ITEM}"
The result will be that the steps context now has the data from the previous step.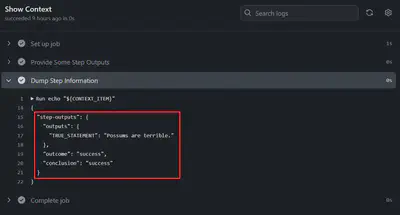
You can see it’s just a JSON object and step id is the key, that is being put in the JSON object. It has to have something or else every single step that was logged here would look exactly the same and it would be ambugious.
That is why GitHub Actions enforces that if you don’t include an id, it would not log anything at all.
The context information in conjunction with conditional expressions can control the execution of various steps based on branch names, input parameters, and the success or failure of previous steps. It allows for sophisticated automation workflows that can react appropriately to different scenarios during CI/CD processes.
Global Environment Variables
Workflows allows us to define environment variables at the global level as well. These variables are then accessible to all jobs.
name: Environment Variables
on:
push:
branches: feature/global-env
env:
GLOBAL_VAR: test
jobs:
first-job:
name: A Job
timeout-minutes: 5
runs-on: ubuntu-latest
steps:
- name: Output Global Variable
run: echo "${GLOBAL_VAR}"
second-job:
name: Another Job
timeout-minutes: 5
runs-on: ubuntu-latest
steps:
- name: Output Global Variable
run: echo "${GLOBAL_VAR}"
The result will be a variable available across all jobs.
Workflow Defaults
Default options exist for jobs and steps within a workflow. Currently you can define the shell and working-directory
name: Using Defaults
on:
push:
branches: feature/defaults
jobs:
first-job:
name: First Job
timeout-minutes: 5
runs-on: ubuntu-latest
steps:
- name: Create Source Directory
run: mkdir src
shell: bash
- name: Use Python
run: import os; print("I'm running python! Hissssss! " + os.getcwd());
shell: python
working-directory: src
- name: Use Bash
run: echo "I'm running hum-drum bash in $(pwd). Booo."
shell: bash
working-directory: src
- name: Use Bash Also
run: echo "I'm running bash also, but elsewhere in $(pwd). Booo."
shell: bash
second-job:
name: Second Job
timeout-minutes: 5
runs-on: ubuntu-latest
steps:
- name: Create Source Directory
run: mkdir src
shell: bash
- name: Use Bash
run: echo "I'm running bash in $(pwd). So sad."
shell: bash
working-directory: src
The result will be an execution which utilizes bash for most of the steps within the jobs.
We could have defaults at the job level:
name: Using Defaults
on:
push:
branches: feature/defaults
jobs:
first-job:
name: First Job
timeout-minutes: 5
runs-on: ubuntu-latest
defaults:
run:
shell: bash
working-directory: src
steps:
- name: Create Source Directory
run: mkdir src
working-directory: .
- name: Use Python
run: import os; print("I'm running python! Hissssss! " + os.getcwd())
shell: python
- name: Use Bash
run: echo "I'm running hum-drum bash in $(pwd). Booo."
- name: Use Bash Also
run: echo "I'm running bash also, but elsewhere in $(pwd). Booo."
working-directory: ..
second-job:
name: Second Job
timeout-minutes: 5
runs-on: ubuntu-latest
steps:
- name: Create Source Directory
run: mkdir src
shell: bash
working-directory: .
- name: Use Bash
run: echo "I'm running bash in $(pwd). So sad."
shell: bash
working-directory: src
The result will be less code in your workflow, while the execution still performed the same. It used bash as the default shell and provided a default working directory of src.
We could also utilize defaults at the workflow level:
name: Job Default
on:
push:
branches: feature/defaults
defaults:
run:
shell: bash
working-directory: src
jobs:
first-job:
name: First Job
timeout-minutes: 5
runs-on: ubuntu-latest
steps:
- name: Create Source Directory
run: mkdir src
working-directory: .
- name: Use Python
run: import os; print("I'm running python! Hissssss! " + os.getcwd())
shell: python
- name: Use Bash
run: echo "I'm running hum-drum bash in $(pwd). Booo."
- name: Use Bash Also
run: echo "I'm running bash also, but elsewhere in $(pwd). Booo."
working-directory: ..
second-job:
name: Second Job
timeout-minutes: 5
runs-on: ubuntu-latest
steps:
- name: Create Source Directory
run: mkdir src
working-directory: .
- name: Use Bash
run: echo "I'm running bash in $(pwd). So sad."
The result will be even less code, making bash the default shell and src the working-directory for all job steps.
Dependent Jobs
Jobs by default run in parallel/asynchronously. If you need synchronous execution, you specify the dependencies via the needs keyword. The job will only execute after all jobs listed in the needs array have completed successfully. If any of the jobs in the needs list fail, the dependent job will not run.
Additionally, jobs chained in series could also share outputs. This is done through the outputs field in a job and accessed via the needs.<job_id>.outputs.<output_name> syntax.
name: Dependent Jobs
on:
push:
branches: feature/dependent
jobs:
first-job:
name: First Job (parallel)
timeout-minutes: 5
runs-on: ubuntu-latest
outputs:
random-uuid: ${{ steps.uuid-gen.outputs.UUID }}
steps:
- name: Random UUID Gen
id: uuid-gen
run: echo "UUID=$(uuidgen)" >> "$GITHUB_OUTPUT"
- name: Dump Job Information
env:
CONTEXT_ITEM: ${{ toJson(job) }}
run: echo "${CONTEXT_ITEM}"
second-job:
name: Second Job (series)
timeout-minutes: 5
runs-on: ubuntu-latest
needs: first-job
steps:
- name: Dump Job Information
env:
CONTEXT_ITEM: ${{ toJson(job) }}
run: echo "${CONTEXT_ITEM}"
- name: Output UUID Information
run: echo " The random UUID from the job is '${{ needs.first-job.outputs.random-uuid }}'." >> $GITHUB_STEP_SUMMARY
third-job:
name: Third Job (parallel)
timeout-minutes: 5
runs-on: ubuntu-latest
steps:
- name: Dump Job Information
env:
CONTEXT_ITEM: ${{ toJson(job) }}
run: echo "${CONTEXT_ITEM}"
Pull Request Triggers
GitHub Actions provides two distinct events for handling pull requests: pull_request and pull_request_target. Both can trigger workflows in response to pull request activity, but they differ significantly in their security contexts, usage scenarios, and access to repository secrets.
pull_requestEvent
Behavior:
- Triggered by events related to pull requests, such as opening a pull request, editing it, or changing its status (e.g., merging or closing).
- Runs in the context of the forked repository. This means that workflows do not have access to the secrets defined in the base repository (the repository where the pull request is being merged).
- More secure by design, preventing potentially malicious code from accessing sensitive data in the base repository.
Use Case:
You have a public repository where contributors can submit pull requests. You want to run tests to validate the code quality and ensure it meets certain standards before it can be merged. Here’s a sample workflow.yml file that uses the
pull_requestevent:name: PR Guidelines and CI on: pull_request: types: [opened, synchronize, reopened] permissions: pull-requests: write jobs: post-guidelines-comment: name: Post guidelines comment timeout-minutes: 5 runs-on: ubuntu-latest steps: - run: gh pr comment $PR_URL --body "$COMMENT_BODY" env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} PR_URL: ${{ github.event.pull_request.html_url }} COMMENT_BODY: | Thank you for your contribution! Please ensure you have followed our community guidelines and the pull request checklist: **Community Guidelines:** - Be respectful and considerate to others. - Follow the project's code of conduct. **Pull Request Checklist:** - [ ] I have read and understood the community guidelines. - [ ] My code follows the existing style of the project. - [ ] I have included tests for new features and bug fixes. - [ ] I have updated the documentation accordingly. - [ ] I have tested my changes locally. If you have any questions, feel free to reach out! test: name: CI runs-on: ubuntu-latest needs: post-guidelines-comment # Ensure this job runs after posting the comment steps: - name: Check out code uses: actions/checkout@v2 - name: Install dependencies run: npm install - name: Run tests run: npm test
- The step
post-guidelines-commentuses GitHub CLI (gh) to add a comment when a pull request is opened. To allow GitHub CLI to post a comment, we set the GITHUB_TOKEN environment variable to the value of the GITHUB_TOKEN secret, which is an installation access token, created when the workflow runs. For more information, see Automatic token authentication. We set thePR_URLenvironment variable to the URL of the newly created pull request, and we use this in theghcommand. - By default, workflows have a restricted set of permissions. Explicitly setting
pull-requests: writeallows the workflow to perform actions that modify pull requests, such as posting comments or updating labels.
pull_request_targetEvent
Behavior:
Also triggered by pull request related events, similar to pull_request. But runs in the context of the base repository. This allows workflows to have access repository secrets defined in the base repository.
Because it has access to sensitive information, it is crucial to be careful with what code is executed in this context, as it could be exploited if the pull request comes from an untrusted fork.
Use Case:
Imagine you have a repository that needs to run a deployment script or access sensitive tokens (e.g., AWS credentials) when a pull request is made. You can use the
pull_request_targetevent to run such workflows while ensuring only trusted code runs. Here’s how you might set it up:name: Deploy on: pull_request_target: types: [opened, synchronize] jobs: deploy: runs-on: ubuntu-latest if: ${{ github.event.pull_request.head.repo.fork == false }} # Run only for non-fork PRs steps: - name: Check out code uses: actions/checkout@v2 - name: Run deployment script env: DEPLOY_TOKEN: ${{ secrets.DEPLOY_TOKEN }} run: | # Run deployment commands here ./deploy.sh
You add a conditional check:
(if: ${{ github.event.pull_request.head.repo.fork == false }})
to the deploy job. This will prevent the deployment job from executing if the pull request comes from a forked repository, thereby mitigating potential security risks.
Workflow Dispatch Triggers
Workflow Dispatch allows the user to manually trigger a GitHub Actions workflow. Let’s see an example that allows you to manually trigger a release creation using a specific tag.
From the default branch of your repository, create a new branch of code called
feature/dispatch-workflow.Create a new file named
.github/workflows/create-release.yaml(make sure you are editing the file in feature/dispatch-workflow).Copy the contents below to the newly created file:
name: Create Release on: workflow_dispatch: inputs: tag: type: string required: true description: Tag for the release. default: "0.1.0" permissions: contents: write jobs: create-release: timeout-minutes: 5 runs-on: ubuntu-latest steps: - run: gh release create $TAG --repo https://github.com/$GITHUB_REPOSITORY --target $COMMITISH --generate-notes env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} TAG: ${{ inputs.tag }} COMMITISH: ${{ github.ref }}Commit the file.
The step you’ve added uses GitHub CLI (gh) to create a release using the tag name you provided in the input. This will create a git tag using the Target branch or full commit SHA (default branch if none is provided). If a matching git tag does not yet exist, one will automatically get created from the latest state in the target ref.
To allow GitHub CLI to execute, we set the GITHUB_TOKEN environment variable to the value of the GITHUB_TOKEN secret, which is an installation access token, created when the workflow runs. For more information, see Automatic token authentication.
We set the TAG, COMMITISH environment variables to prevent script injection. See Security for GitHub Actions to understand why we use env variables instead of referencing the variable directly in the run step.
Create a Pull Request, set base:
mainand compare:feature/dispatch-workflowMerge your workflow file.
Run the workflow to create a release:
- Select
Create Releaseworkflow from the left sidebar. - Click on the
Run workflowbutton. - Leave the branch as
defaultand give atagname. - Wait for the workflow to run and check if a release has been created.
- Select
Matrices
Defining a matrix strategy in a workflow allow you to essentially define a template job and scale out job execution based on variables you define. This is incredibly useful for repeating the same job but with slightly different values, like if you needed to test software against different versions of a language, against multiple os versions, multiple browsers, different database engines and so on.
Let’s say we have a NodeJS application and we want to run our tests against the following:
- Node.js versions:
14,16,18 - Operating systems:
ubuntu-latestandwindows-latest
We define a strategy section that includes a matrix with two axes: node-version and os.
This matrix indicates that we want to run the job for each combination of the specified Node.js versions and operating systems.
name: Node.js CI
on: [push, pull_request]
jobs:
build:
runs-on: ${{ matrix.os }}
strategy:
matrix:
node-version: [14, 16, 18]
os: [ubuntu-latest, windows-latest]
steps:
- name: Check out the code
uses: actions/checkout@v2
- name: Set up Node.js
uses: actions/setup-node@v2
with:
node-version: ${{ matrix.node-version }}
- name: Install dependencies
run: npm install
- name: Run tests
run: npm test
When this workflow runs, GitHub Actions will create a total of 6 job executions:
- Node.js 14 on Ubuntu
- Node.js 14 on Windows
- Node.js 16 on Ubuntu
- Node.js 16 on Windows
- Node.js 18 on Ubuntu
- Node.js 18 on Windows
Caching
GitHub Actions provides a caching mechanism that helps speed up workflow runs by storing dependencies and other files that are expensive to rebuild or download. By caching certain files, you can significantly reduce the execution time of your CI/CD workflows, particularly in scenarios where you install dependencies, compile code, or generate build artifacts.
How Caching Works
Cache Key: Each cache is identified by a
key. You can define the key using specific identifiers, such as the dependency version, operating system, or branch name, which allows you to manage cache versions effectively.Save Cache: In a workflow, you can specify which files or directories to cache. When the workflow runs, it saves the specified files to the cache under the defined key.
Restore Cache: When a workflow runs, it first checks for the cache that matches the key. If a matching cache is found, it restores those files before executing any subsequent steps, allowing you to skip expensive operations.
Cache Hits and Misses: If the cache key matches a previously saved cache, it’s called a cache hit; otherwise, it’s a cache miss. In the case of a cache miss, the files specified for caching are rebuilt or redownloaded, and a new cache is created.
Here’s an example of using caching in a GitHub Actions workflow for a Node.js application. In this workflow, we will cache the node_modules directory to speed up the installation of dependencies.
name: Node.js CI
on:
pull_request:
branches: [main]
permissions:
contents: read
id-token: write
jobs:
first-job:
timeout-minutes: 5
name: Build and test!
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v4
- name: Setup node version 20
uses: actions/setup-node@v2
with:
node-version: 20
- name: Cache node modules
id: cache-npm
uses: actions/cache@v4
env:
cache-name: cache-node-modules
with:
# npm cache files are stored in `~/.npm` on Linux/macOS
path: ~/.npm
key: ${{ runner.os }}-build-${{ env.cache-name }}-${{ hashFiles('**/package-lock.json') }}
restore-keys: |
${{ runner.os }}-build-${{ env.cache-name }}-
${{ runner.os }}-build-
${{ runner.os }}-
- if: ${{ steps.cache-npm.outputs.cache-hit != 'true' }}
name: List the state of node modules
continue-on-error: true
run: npm list
- name: Install dependencies
run: npm install
- name: Test
run: npm test
The first job Cache node modules attempts to load cached npm files by generating a UID key and checking it against the key in our cached objects. In this case, they key is the runner os, cache name, and a SHA-256 hash of the package-lock.json file.
- When key exactly matches an existing cache, it’s called a cache hit, and the action restores the cached files to the path directory.
- When key doesn’t match an existing cache, it’s called a cache miss, and a new cache is automatically created if the job completes successfully.
Limitations While caching can greatly enhance performance, there are some limitations:
- Cache Size: The maximum size for a single cache is 10 GB.
- Branch Specificity: Caches are branch-specific, meaning they are not shared across branches by default.
- 7-Day Retention: Caches have a 7-day rolling retention period; if not accessed in this timeframe, they may be deleted.
- Restore Performance: Restoring caches can sometimes be slower than expected if the cache is large or not found.
- Sensitive Data: Avoid caching sensitive information to prevent exposure.
Composite Actions
Composite Actionsallow you to collect a series of workflow jobstepsinto a single action which you can then run as a single job step in multiple workflows.Composite actions are meant to be generic and isolated but reused commonly throughout your organization. They have some limitations:
- Cannot use
secretsunless they are passed in - Cannot use multiple jobs
- Cannot use
Some good candidates for composite actions are compliance checks, linters, environment setup, or preflight checks that are common to many workflows.
To give an example let’s set up a Repository Structure:
setup-node-environment-action/ ├── action.yml └── README.mdThe
action.ymlfile defines the action and its inputs/outputs:name: 'Environment Setup' description: 'Prep our environment' inputs: node-version: # id of input description: 'What version of node to install' required: true default: '20' cache: description: 'Whether to cache node modules (true/false).' required: false default: 'true' runs: using: "composite" steps: - name: Check out repository code uses: actions/checkout@v4 - name: Setup node version $INPUT_NODE_VERSION uses: actions/setup-node@v2 with: node-version: ${{ inputs.node-version }} cache: ${{ inputs.cache }}Push to the remote repository on GitHub.
Now that your standalone action is published, you can use it in any other repository by referencing it in your workflows:
name: CI Workflow on: push: branches: - main pull_request: jobs: build: runs-on: ubuntu-latest steps: - name: Setup Node.js Environment uses: <your-username>/setup-node-environment-action@main # Reference your action with: node-version: '16' # Specify the desired Node.js version. install-dependencies: 'true' cache: 'true' - name: Run Tests run: npm test # Adjust according to your project's test script
Reusable Workflows
Reusable workflows allow you to reuse an entire workflow, including all of its jobs and steps. This is particularly useful when you have a complete CI/CD process that you want to use across multiple repositories. Reusable workflows can be centrally maintained, in one location, but used in many repositories across your organization.
- Create a new repository for your reusable workflow. You can name it something like
nodejs-setup-workflow.nodejs-setup-workflow/ ├── .github/ │ └── workflows/ │ └── setup-node.yml └── README.md - In the
setup-node.ymlfile, define your reusable workflow for setting up a Node.js environment:name: Setup Node.js Environment on: workflow_call: inputs: node-version: required: true type: string install-dependencies: required: false type: boolean default: true cache: required: false type: boolean default: true jobs: setup: runs-on: ubuntu-latest steps: - name: Checkout Repository uses: actions/checkout@v2 - name: Set up Node.js uses: actions/setup-node@v2 with: node-version: ${{ inputs.node-version }} cache: ${{ inputs.cache }} - name: Install Dependencies if: ${{ inputs.install-dependencies }} run: npm install - name: Run Build run: npm run build # Optional: Adjust according to your project's build script - To invoke this reusable workflow in another GitHub repository, you can create a new workflow file (e.g.,
.github/workflows/ci.yml) that references the reusable workflow:name: CI Workflow on: push: branches: - main pull_request: jobs: build: uses: <your-username>/nodejs-setup-workflow/.github/workflows/setup-node.yml@main # Reference your reusable workflow with: node-version: '16' # Specify the desired Node.js version. install-dependencies: true cache: true
Further Read
That’s all for now. Consider Intro to GitHub Actions complete, but there’s a long ways to go and lots more to learn.