Run Code Serverless
Overview
Lambda is a compute service where you can upload your code and create a lambda function. AWS Lambda takes care of the provisioning and managing the servers that you use to run your code so you don’t have to worry about operating systems patching scaling etc. You can use lambda in the following ways:
- Lambda can act as an event driven compute service where AWS lambda runs your code in response to events. These events could be anything, could be changes to your data in S3 or it could be a change to your data in a DynamoDB table etc..
- As a compute service to run your code in response to HTTP requests using Amazon APIGateway, Application Load Balancer (ALB) or API calls made using the AWS SDK.
Features
- Lambda scales out (NOT UP) automatically.
- Lambda functions are independent, i.e. 1 event = 1 function
- Lambda is serverless.
- Lambda functions can trigger other Lambda functions, 1 event = x functions if functions trigger other functions.
- Architectures can get extremely complicated, AWS X-ray allows you to debug what is happening.
- Lambda can do things globally so you can use it to back up a S3 bucket to other S3 buckets etc. It’s not stuck in one region. You can use it all across the AWS ecosystem.
Permissions
Two sides to access permission
Permissions to invoke the functions
What the function is permitted to do

Execution role gives Lambda permission to interact with other services
- Selected or created when you create a Lambda function
- IAM policy includes actions that Lambda can do with the resource
- Trust policy that allows Lambda to AssumeRole
- Creator must have permission for iam:PassRole
Resource policy gives other services permission to invoke Lambda functions
- Policy associated with a “push” event source
- Created when you add a trigger to a Lambda function
- Allows the event source to take the lambda:InvokeFunction action
Event sources
- An event source is the entity that publishes events, and a Lambda function is the custom code that processes the events. Configuration of services as event triggers is referred to as Event Source Mapping

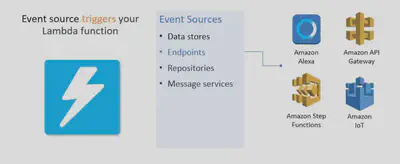


- Each of the event sources will invoke Lambda in one of these execution models:

Notes:
- When invoking a Lambda function programmatically, you must specify the invocation type.
- When AWS services are sources, the invocation type is predetermined.
- The Lambda console shows all event sources for a given function.
- When you select Test from the Lambda console, it always invokes your Lambda function synchronously.
Push Events
Synchronousvs.Asynchronousevent sourcesSynchronous Event Sources
- Synchronous events expect an immediate response from the function invocation.
- With this execution model, there is no built-in retry in Lambda. You must manage your retry strategy within your application code.
- To invoke Lambda synchronously via API, use RequestResponse invocation type.
Examples of AWS services that invoke Lambda
synchronously-User Invoked:
- Elastic Load Balancing (Application Load Balancer)
- Amazon API Gateway
- Amazon CloudFront (Lambda@Edge)
- Amazon S3 Batch
Service Invoked:
- Amazon Cognito
- AWS Step Functions
Other Services:
- Amazon Lex
- Amazon Alexa
- Amazon Kinesis Data Firehose
Asynchronous Event Sources
- Asynchronous events are placed in an Event Queue, and the requestor doesn’t wait for the function to complete.
- This model makes sense for batch processes. With an async event, Lambda automatically retries the invocation twice more on your behalf. You also have the option to enable a
Dead Letter Queue(DLQ) on your Lambda function. - Make sure the processing is idempotent (in case of retries)
- There are two error handling options to give you more control over failed records from asynchronous event sources:
Maximum Event AgeandMaximum Retry Attempts. - To invoke functions asynchronously via API, use Event invocation type.
Examples of AWS services that invoke Lambda asynchronously -
- Amazon Simple Storage Service (Amazon S3)
- Amazon Simple Notification Service (Amazon SNS)
- Amazon Simple Email Service (Amazon SES)
- Amazon CloudWatch Logs
- AWS CloudFormation
- Amazon CloudWatch Events
- AWS CodeCommit
- AWS Config
- AWS Internet of Things (IoT) button
Checkout CLI references here: Lambda-CLI
Polling Events
- Three services use the polling model:
DynamoDB Streams,KinesisandSQS. - In this model the events put information onto the stream or queue respectively.
- Event Source Mapping will poll SQS queues or streams at regular intervals.
- Your Lambda function is invoked synchronously

Streams

- Stream-based polling there is no cost to make the polling calls.
- An Event Source Mapping creates an iterator for each
shard, processes items in-order - Start with new items, from the beginning or from timestamp
- Processed items aren’t removed from the stream (other consumers can read them)
- Low traffic: use batch window to accumulate records before processing
- You can process multiple batches in parallel
- up to 10 batches per shard
- in-order processing is still guaranteed for each partition key,
- With streams, errors in a shard block further processing: – A failure in this model blocks Lambda from reading any new records from the stream until the failed batch of records either expires or is processed successfully. This is important because the events in each shard from the stream need to be processed in order.
- Scaling:
- One Lambda invocation per stream
shard - If you use parallelization, up to 10 batches processed per shard simultaneously
- One Lambda invocation per stream
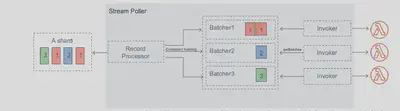
Queues

- With SQS polling, standard SQS rates apply for each request.
- Event Source Mapping will poll SQS (Long Polling)
- Specify batch size (1-10 messages)
- Recommended: Set the queue visibility timeout to 6x the timeout of your Lambda function
- Lambda deletes the items from the queue after they are processed successfully.
- To use a DLQ set-up on the
SQSqueue, not the Lambda (DLQ for Lambda is only for async invocations) - Or use a Lambda Destination for failures
- With queues, errors in a batch are returned to queue
- Lambda will keep retrying a failed message until it is processed successfully, or the retries or retention period are exceeded. If the message fails all retries, it will either go to the DLQ if configured, or it will be discarded. An error doesn’t stop processing of the batch, but there may be a change to the order in which messages are processed.
- Occasionally the Event Source Mapping might receive the same item from the queue twice, even if no function error occurred. So we need to make sure the Lambda is processing the messages in a idempotent fashion.
- Scaling:
- SQS Standard:
- Lambda scales up to process a
Standard Queueas early as possible. It adds 60 more instances per minute to scale up. - Up to 1000 batches of messages processed simultaneously
- Lambda scales up to process a
- SQS FIFO:
- Messages with the same GroupID will be processed in-order
- The Lambda function scales to the number of active message groups
- SQS Standard:
Lambda – Destinations
You can configure to send result to a destination
Asynchronous invocations - can define destinations for successful and failed event:

- Amazon SQS
- Amazon SNS
- AWS Lambda
- Amazon EventBridge bus
Note: AWS recommends you use Destinations instead of DLQ now (but both can be used at the same time)

Event Source mapping: for discarded event batches
- Amazon SQS
- Amazon SNS
Note: you can send events to a DLQ directly from SQS
Lifecycle of a Lambda function
When a function is first invoked, an execution context is launched and bootstrapped. This execution context initializes any external dependencies of your lambda code, database connections, HTTP clients, SDK client etc. Once the context is bootstrapped, your function code executes. Then, Lambda freezes the execution context, expecting additional invocations. The execution context includes the
/tmpdirectoryIf another invocation request for the function is made while the environment is in this state, that request goes through a warm start. With a warm start, the available frozen container is thawed and immediately begins code execution without going through the bootstrap process.
This thaw and freeze cycle continues as long as requests continue to come in consistently. But if the environment becomes idle for too long, the execution environment is recycled.
A subsequent request starts the lifecycle over, requiring the environment to be launched and bootstrapped. This is a cold start.
In 2019, AWS introduced provisioned concurrency to give the ability to keep a number of environments warm to prevent cold starts from impacting your function’s performance.
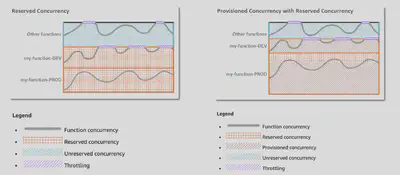
Lambda Concurrency and Throttling
Concurrency limit: up to 1000 concurrent executions
Can set a Reserved Concurrency at the function level (=limit)
Each invocation over the concurrency limit will trigger a
ThrottleThrottle behavior:
- If synchronous invocation => return ThrottleError - 429
- If asynchronous invocation => retry automatically and then go to DLQ
If you need a higher limit, open a support ticket
Cold Start:
- New instance => code is loaded and code outside the handler run (init)
- If the init is large (code, dependencies, SDK…) this process can take some time.
- First request served by new instances has higher latency than the rest
Provisioned Concurrency:
- Concurrency is allocated before the function is invoked (in advance)
- So the cold start never happens and all invocations have low latency
- Application Auto Scaling can manage concurrency (schedule or target utilization)
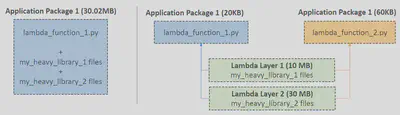
Lambda Layers
You can configure your Lambda function to pull in additional code and content in the form of layers. A layer is a .zip file archive that contains libraries, a custom runtime, or other dependencies. With layers, you can use libraries in your function without needing to include them in your deployment package.
Custom Runtimes
Externalize Dependencies to re-use them:
Authoring Lambda functions
With Lambda, you can use the language and IDE that you are most familiar with and bring code you’ve already written. The code may need some adjustments to make it serverless.
Start with the handler method: The handler method is the entry point that AWS Lambda calls to start executing your Lambda function. The handler method always takes two objects: the event object and the context object.
Event Object
- The event object provides information about the event that triggered the Lambda function. This could be a pre-defined object that an AWS service generates, or it could be a custom user-defined object in the form of a serializable string. For example, it could be a pojo or a json stream.

- The event object provides information about the event that triggered the Lambda function. This could be a pre-defined object that an AWS service generates, or it could be a custom user-defined object in the form of a serializable string. For example, it could be a pojo or a json stream.
Context Object
- The context object is generated by AWS, and provides metadata about the execution. You can use it to interact with Lambda. For example, it includes awsRequestld, logStreamName, and the getRemainingTimeInMillis() function.

- The context object is generated by AWS, and provides metadata about the execution. You can use it to interact with Lambda. For example, it includes awsRequestld, logStreamName, and the getRemainingTimeInMillis() function.
Here’s an example of Event & Context Objects using Python

Perform heavy-duty work outside of your function handler
- Connect to databases outside of your function handler
- Initialize the AWS SDK outside of your function handler
- Pull in dependencies or datasets outside of your function handler

Use environment variables for:
- Database Connection Strings, S3 bucket, etc… don’t put these values in your code
- Passwords, sensitive values… they should be encrypted using KMS
If your Lambda function needs disk space to perform operations, you can make use the
/tmpdirectory. The directory content remains when the execution context isfrozen, providing transient cache that can be used for multiple invocations.(helpful to checkpoint your work). For permanent persistence of object (non temporary), use S3.Minimize your deployment package size to its runtime necessities.
- Break down the function if need be
- Remember the AWS Lambda limits
- Use Layers where necessary
Avoid using
recursivecode, never have a Lambda function call itself
Version Control With Lambda
- When you use versioning with AWS Lambda you can publish one or more versions of your lambda functions. As a result you can work with different variations of your Lambda function in your development workflow, such as Dev, Prod, Beta and so on.
- Each Lambda function
versionhas an unique ARN. After you publish a version it becomesimmutable. - AWS Lambda maintains your latest code in the
$LATESTversion. - After creating your Lambda function (the $LATEST version), you can publish a Version 1 of it.
- You can refer to your Lambda function using it’s ARN. There are 2 ARNs associated with the Lambda function:
- Qualified ARN - The function ARN with the version suffix: e.g arn:aws:lambda:us-west-1:396087960458:function:SendMessageFunction:v1
- UnQualified ARN - The function ARN without the version suffix: e.g arn:aws:lambda:us-west-1:396087960458:function:SendMessageFunction
- When you invoke a function using an UnQualified ARN, Lambda implicitly invokes $LATEST.
- You could also create
Aliasesfor your Lambda function. They are pointers to Lambda function versions. You can’t use an UnQualified ARN to create an alias. - We can define a DEV, TEST, PROD aliases and have them point to different lambda versions.
- Aliases are
mutable - By creating an
Aliasnamed PROD that points to V1, you can now use the PROD alias to invoke V1 version of the Lambda function. - You can update the code (the $LATEST version) with improvements and then publish a V2. You can promote V2 to production by remapping the PROD alias so that it points to V2 now. If there was any issue, you can easily rollback to V1 by remapping back.
- Aliases enable Canary deployment by assigning
weightsto lambda functions - Aliases enable stable configuration of our event triggers / destinations
- Aliases have their own
ARNs - Aliases cannot reference other aliases
- You cannot split traffic with $LATEST version, instead create an Alias to latest and split that way.

Monitoring
In the below sections we will describe few of the tools available to help you monitor and troubleshoot your Lambda functions.
CloudWatch Metrics
CloudWatch provides 7 metrics out of the box for lambda functions to help you identify at a high level how your functions are performing, errors being generated, and the overall health of your application:
- Invocations - Number of times a function is invoked in response to an event or invocation API call.
- Errors - Number of invocations that failed due to errors in the function (response code 4XX).
- Duration - Elapsed time from when the function code starts executing to when it stops executing.
- Throttle - Number of Lambda function invocation attempts that were throttled due to invocation rates exceeding the customer’s concurrent limits (error code 429).
- Iterator Age - Emitted for stream-based invocations only. Measures the age of the last record for each batch of records processed. Age is the difference between the time Lambda received the batch and the time the last record in the batch was written to the stream.
- ConcurrentExecutions - Measures the sum of concurrent executions for a given function at a given point in time. Must be viewed as an average metric if aggregated across a time period.
- UnreservedConcurrentExecutions - Represents the sum of the concurrency of the functions that do not have a custom concurrency limit specified. Must be viewed as an average metric if aggregated across a time period.
CloudTrail Logs
Logs API calls made by or on behalf of a function
- Audit actions made against your application
- Integrate with a CloudWatch rules to respond to audit findings
- Export for additional analysis
- CloudTrail can be an important tool for auditing serverless deployments and rolling back unplanned deployments.
Dead Letter Queues
Dead Letter Queues (DLQs) help you capture application errors that you cannot just discard but must respond to.
- Use DLQs to analyze failures for follow-up or code corrections.
- Available for asynchronous and non-stream polling events
- Can be an Amazon
SNStopic or AmazonSQSqueue
X-Ray
AWS
X-Rayis a service that collects data about your requests that your application serves and it provides you with tools you can use to view filter and gain insights into that data to identify issues and opportunities for optimization.Enable in Lambda configuration (
Active Tracing). Runs the X-Ray daemon for youUse AWS X-Ray SDK in Code.
Ensure Lambda Function has a correct IAM Execution Role - The managed policy is called
AWSXRayDaemonWriteAccessEnvironment variables to communicate with X-Ray
- _X_AMZN_TRACE_ID: contains the tracing header
- AWS_XRAY_CONTEXT_MISSING: by default, LOG_ERROR
- AWS_XRAY_DAEMON_ADDRESS: the X-Ray Daemon IP_ADDRESS:PORT
Lambda Limits - per region
Execution:
- Memory allocation: 128 MB – 10 GB MB (1 MB increments). The more RAM you add, the more vCPU credits you get.
- Maximum execution time: Default 3 secs - 900 seconds (15 minutes)
- Environment variables (4 KB)
- Disk capacity in the “function container” (in
/tmp): 512 MB - Concurrency executions: 1000 (can be increased)
Deployment:
- Lambda function deployment size (compressed .zip): 50 MB
- Size of uncompressed deployment (code + dependencies): 250 MB
- Can use the
/tmpdirectory to load other files at startup. Max size is 10GB. - Size of environment variables: 4 KB
Lambda VPC Access


- By default, your Lambda function is launched outside of your own
VPC(in an AWS-owned VPC) - Therefore it cannot access resources in your VPC (RDS, ElastiCache, internal ELB…)
- In order to give access for
Lambdato yourVPCresources, you need to associate the Lambda function to the VPC, specify the Subnets and the Security Groups. - Lambda will create an
ENI(Elastic Network Interface) in your subnets. - Lambda would need
AWSLambdaVPCAccessExecutionRoleto be able to create ENI
Lambda in VPC – Internet Access
- A Lambda function in your VPC does not have internet access
- Deploying a Lambda function in a public subnet does not give it internet access or a public IP
- Deploying a Lambda function in a private subnet gives it internet access if you have a NAT Gateway / NAT Instance
- You can use
VPC endpointsto privately access AWS services without a NAT (say aDynamoDBtable)
Note: Lambda - CloudWatch Logs works even without VPC endpoint or NAT Gateway


Lambda and CloudFormation
- You could define your Lambda function in a CloudFormation template inline. Functions have to be simple. (Cannot include function dependencies with inline functions)
- Use the
Code.ZipFileproperty - You could also store the Lambda function as a zip in
S3and refer the S3 zip location in the CloudFormation code:- S3Bucket:
- S3Key:
- S3ObjectVersion:
(if versioned bucket)
- S3Bucket:
- If you update the code in S3, but don’t update S3Bucket, S3Key or S3ObjectVersion, CloudFormation won’t update your function
